
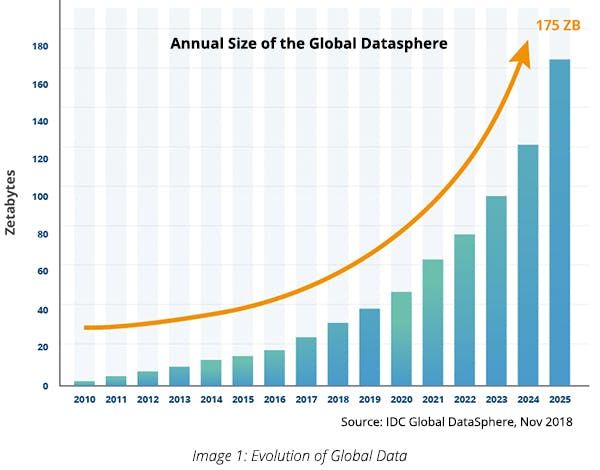
With digital advancements, data is growing at an exponential rate every day. This has changed how businesses grow and interact with each other and their consumers. Data can be used to measure ROI and it can also be used to obtain information on consumers and competitors. The amount of clean data a company has can be the difference between success and failure. So what is the difference between structured and unstructured data?
The amount of data available and the scale at which it is generated has presented both a challenge and an opportunity for all companies, especially within the financial services industry. Asset, quantitative, and wealth management firms rely on large amounts of data from various sources to be able to predict price movement in the stock market. While banks and insurance companies must collect data on consumers to keep them satisfied with personalized services and competitors to understand their product offerings.
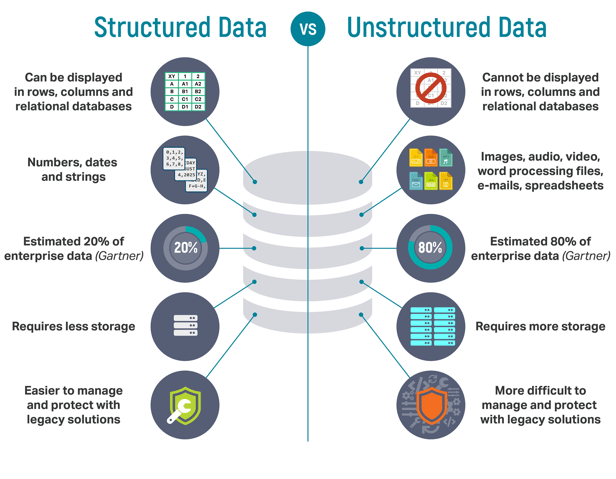
The growth in data can act as a double-edged sword for many financial services firms. Large amounts of data come in various formats and are either structured or unstructured. While structured data makes up about 20%, unstructured data accounts for more than 80% of data generated. Both types of data are important and must be analyzed and interpreted for accurate insights and results. So what is the difference between structured and unstructured data?
Structured Vs Unstructured Data
Structured data is data that appears in pre-defined models. It is organized and fits into templates and spreadsheets, making it easy to analyze. In contrast, unstructured data is not predefined and the data has no form or system to follow. It can come in the form of images, videos, text, and audio, and can be challenging to analyze.What Is Structured Data?
Structured data is text that is organized into columns, tables, or rows, making it easy to analyze manually or by using data analytics tools. The information within structured data is formatted and input into a template that has a design and can fit into a set structure. It resides in relational databases or data warehouses and is easily recognizable by search engines like Google. The content is also easy to understand since it is in a standard format.
Examples of structured data include dates, credit card numbers, phone numbers, addresses, customer names, product names and numbers, currency, gender, and transaction information. Structured data can be found in SQL databases, spreadsheets, sensors, online forms, spreadsheets, point of sale systems, and web and server logs.
Advantages of Structured Data:
The main advantages of structured data include:
- Easily understood by machine learning algorithms- The organized and detailed format of structured data makes it easy to manipulate and pull specific data.
- Easily understood and used by business users- Structured data can be understood and used by an average business user who has an understand of the related data topic. Business users can search through structured data sets and analyze the data manually, without the need for analytic tools or technical-heavy labor.
- Offers more accessibility to tools- Prior to digitalization, structured data was the only form of data available. It has also been used longer by business users, data analysts, computer scientists, and business leaders. Therefore, more tools are available to test, use, and analyze structured data.
Disadvantages of Structured Data:
Although structured data has its advantages, it also has its cons:
- Not as insightful- Structured data does not provide the specific details in data analytics, making it harder to form specific, detailed insights.
- Limited- Structured data only makes up 20% of digital data today. Additionally, because structured data is formatted, changing the data may take a lot of time and resources as you'll have to reorganize the data.
Structured data is normally business end users' data of choice due to the simplicity and defined structures of the text. However, due to the limited insights structured data offers, businesses will need both structured and unstructured data in order to maximize insights.
What Is Unstructured Data?
Unstructured data has no predefined framework, structure, or organization. Although unstructured data makes up more than 80% of digital data, it is often difficult and time-consuming to search and analyze. However, once analyzed, the information extracted can provide valuable insights.
Examples of unstructured data include images, audio and video files, reports, text files, surveillance imagery, and emails. Unstructured data can be found in NoSQL databases, data warehouses, data lakes, and applications.
Advantages of Unstructured data:
The main advantages of unstructured data include:
- More flexibility- Due to the undefined format of unstructured data, it can be stored in a variety of formats such as images, audio transcripts, videos, web content, etc. It can also be used for different purposes such as classifying images, text, and sound, input it into predictive models for sentiment, entity, and theme classification, and for text analytics.
- Offers more insights- Although the information is harder to detect and analyze, unstructured data offers valuable insights into a company's customers and competitors.
Disadvantages of Unstructured Data:
The main disadvantages of unstructured data include:
- Time-consuming and expensive- Unstructured data can take a long time to process. It can also be expensive to turn into useful information, as you will need data scientists to structure the data
- Difficult to analyze- Business users and standard databases will not be able to access unstructured data as it is text-heavy or configured in non-recognizable formats. Data analytics specialists are required to identify, extract, and store the data.
- Requires specific tools- Due to the complexity of unstructured data, most data tools cannot ingest it. There are specific data management tools that will be required to manipulate and pull insights from unstructured content.
Most data today is unstructured. Although it is more difficult and time-consuming to identify and extract information from unstructured text, the insights gained are more valuable than structured data. Unstructured data can be complex and must be structured by data scientists.
Due to the increase in unstructured data, businesses are looking to tools like artificial intelligence that can easily structure unstructured data.
 Source: Lawtomated on Medium
Source: Lawtomated on Medium
Using NLP to Structure Unstructured Data
Text analytics, or text mining, is an artificial intelligence (AI) technology that uses natural language processing (NLP) to convert unstructured text in documents and databases into structured and normalized data. Once the unstructured data is structured, it can be analyzed and input into machine learning (ML) algorithms.
Since structured data is already organized and easy to digest, unstructured data can present challenges when attempting to sort because of the various formats and locations of the data. Artificial intelligence platforms can be used to analyze unstructured text by transforming the unstructured data into a structured format.
Unstructured data processing tools like Accern's No-Code AI platform use machine learning algorithms and natural language processing (NLP) techniques to identify and extract information from unstructured text, and analyze the information as a human would. Although humans would take days to structure the unstructured data, Accern's No-Code AI platform enables end-users to categorize and analyze the text in a fraction of the time with complete accuracy.
Accern's Adaptive Natural Language Processing Models
Accern's NLP models deliver quick, timely, and accurate results. Typical NLP models include the following text analysis techniques:
-
Document Classification to automatically classify and transform your documents into a general structure format. The insights extracted from document classification include document titles, source, type, URL, content, and published time.
-
Entity Classification to automatically understand text data and extract names of companies, products, and services, addresses, phone numbers, and other specific information.
-
Theme Classification to automatically identify, classify, and extract information on specific themes or events.
-
Sentiment Analysis to rate the sentiment or emotions (positive, negative, and neutral) around a given text or document. Once properly trained with Accern's sentiment model trainer, sentiment analysis models can tell you how customers actually feel about the specific entity or theme.
-
Relevance Analysis to automatically determine the relevance of entities and themes within your documents.
-
Text Summarization takes large quantities of data and extracts the most relevant details of the text. The most important points within the document are summarized while keeping the meaning of the data.
-
Foreign Language Translations to scan and interpret content in different languages to identify if the text has a positive or negative connotation in financial documents.
For more information on how you can structure unstructured data with NLP, request a demo with the form below.
Request a Demo
About Accern:
Accern enhances AI workflows for financial service enterprises with a no-code data science platform. Researchers, business analysts, data science teams, and portfolio managers use Accern to build and deploy Natural Language Processing (NLP) models with artificial intelligence (AI). The results are that companies cut costs, generate better risk and investment insights, and experience a 24x productivity gain with our industry-leading NLP solutions. Allianz, IBM, and Jefferies utilize Accern to build and deploy AI solutions powered by our adaptive NLP and forecasting features. For more information on how we can accelerate AI adoption for your organization, visit accern.com