A Data Science Perspective
Creating a performant and accurate machine learning model is a strenuous and difficult task. On the shorter end it can take several months until a model can be confidently deployed in production. However, once this happens, the next set of questions appear: Can I trust that the promised performance holds beyond the hold-out data used to validate the training? How long will the model provide good results? Can I apply the model to slightly different but similar tasks? Adaptive modeling can provide answers to all of those questions (techniques, like, e.g., shadow deployment also provide answers but are out of the scope of this post).
Adaptive modeling can be roughly divided into two broad categories: domain adaptation and task adaptation. Following, we will have a brief look at both of these categories before we discuss the implications of an adaptive modeling centered workflow.
Domain Adaptation
When training, for example, an image-recognition machine learning model, we make the implicit assumption that the domain of our data will remain constant throughout the lifecycle of our model. A "cat" will always look like a cat and a "dog" will always look like a dog.  We don't need to worry about having to suddenly be able to identify an entity as "cat" that looks nothing like a cat. For many machine learning tasks this assumption holds true. However, for many other tasks this is not the case. For example, imagine a machine learning task that uses patient data from "Hospital A" to predict disease likelihoods. As it performs very well, people from "Hospital B" want to use the model, too. However, "Hospital A" and "Hospital B" have both different patient demographics and different imaging / laboratory facilities which introduce different biases (e.g., the brightness setting of medical scanners could differ between the hospitals) and thus, the performance of the model on the data of "Hospital B" struggles to achieve the same numbers the model had for "Hospital A". We need to adapt our model to include the new domain (this also overlaps with the machine learning discipline of transfer learning [1][2]).
We don't need to worry about having to suddenly be able to identify an entity as "cat" that looks nothing like a cat. For many machine learning tasks this assumption holds true. However, for many other tasks this is not the case. For example, imagine a machine learning task that uses patient data from "Hospital A" to predict disease likelihoods. As it performs very well, people from "Hospital B" want to use the model, too. However, "Hospital A" and "Hospital B" have both different patient demographics and different imaging / laboratory facilities which introduce different biases (e.g., the brightness setting of medical scanners could differ between the hospitals) and thus, the performance of the model on the data of "Hospital B" struggles to achieve the same numbers the model had for "Hospital A". We need to adapt our model to include the new domain (this also overlaps with the machine learning discipline of transfer learning [1][2]).
Furthermore, even without transferring to an explicitly different domain, the input domain of a task might naturally change over time creating temporal drifts in the data. As contemporary example, an NLP model trained before the year 2020 needed to be updated in the wake of COVID-19. Many habitual changes, resulting from COVID-19, had a wide spread impact on day to day discourse. Therefore, a fallback to a contextual understanding of the word "covid" as a "generic disease" would simply be insufficient. The model needs to be adapted to accommodate those changes to the language (see also Liquid Time-constant Networks [3] which offer a solution to this via a specialized model architecture).
Regularly adapting models is a must to keep machine learning models up to date. However, it is often unclear when exactly a domain or temporal drift has changed the underlying data enough to affect the model's performance. Conversely, updating the model continuously, i.e., each time new ground truth is available, is expensive, slow, and also bears the risk of over-fitting. Instead, triggers can be used that signal when a model needs to be adapted further. Adaptive modeling triggers can range from fixed time intervals to statistical analyses of the input or performance data measuring the significance of the changes. Splitting the input stream of data using those triggers, additionally enables a more realistic continuous monitoring simulation during model exploration and even allows for processing large inputs quicker, thus making adaptive modeling truly big data.
Task Adaptation
Most current machine learning models utilize representation learning [4]. That is, instead of trying to generate hand-crafted features that suit the machine learning task, the data is provided without much manual intervention and the machine is left to learn a helpful representation of the data which is then used to solve the task. Typically, the representation and the task head are unified in one big model. This is unfortunate, though, as big models are harder to train efficiently and require more input data in order to not suffer from under-fitting or insufficient generalization. This makes creating powerful machine learning models from scratch a time consuming and expensive process.
In addition, machine learning tasks are often similar in nature. Take, for example, a model that aims to extract the sentiment of text snippets from social media. Different stakeholders have different expectations on what "positive", "neutral", and "negative" means in their context. A marketing firm that tries to determine customer satisfaction might consider a statement such as "the awesome tech-support helped me setup my new X-Thingy" as being positive while a statement like "Y and Z company join forces to develop the next X-Thingy" would be regarded as neutral. On the other hand, a quantitative trader might see the first statement to be neutral at best and second statement to be positive. Here, we have two similar tasks that only differ in their final interpretation of the outcome. By separating the representation layers of a model from the task head, i.e., inference layers, we can reuse the same representation for both tasks and simply adapt each task head to the right interpretation. This allows models to be extremely reusable. Moreover, the need for a large training set and an expensive and time consuming training process can be pushed to the representation model and has to be done only once (for example, Hugging Face [5] is a public repository for such models, including, e.g., the popular BERT language model [6]). On the other hand, adapting the inference layers for different tasks can be done quickly and without much effort while necessitating only few training examples (commonly referred to as few-shot learning [7]).
Here, we have two similar tasks that only differ in their final interpretation of the outcome. By separating the representation layers of a model from the task head, i.e., inference layers, we can reuse the same representation for both tasks and simply adapt each task head to the right interpretation. This allows models to be extremely reusable. Moreover, the need for a large training set and an expensive and time consuming training process can be pushed to the representation model and has to be done only once (for example, Hugging Face [5] is a public repository for such models, including, e.g., the popular BERT language model [6]). On the other hand, adapting the inference layers for different tasks can be done quickly and without much effort while necessitating only few training examples (commonly referred to as few-shot learning [7]).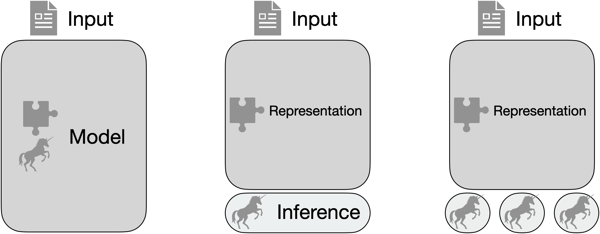
Task adaptive machine learning provides a scalable mechanism to personalize machine learning models and keep their users competitive through exclusive and focused models.
Conclusion
We have seen how adaptive modeling offers a cost-effective and scalable approach to adjust models for individual needs and keep those models up to date in a constantly changing environment. It allows for the creation of a model catalog of common machine learning tasks that can later be personalized for individual needs. This all can be achieved by updating the weights of existing models. Therefore avoiding unfortunate surprises that fully training a new model from scratch could bring.
Lastly, with the help of automatic fail-safes, adaption triggers, and user guidance, stakeholders are empowered to maintain their models without the help of specialists. With adaptive modeling, domain experts can build models that last.
About Accern
Accern enhances artificial intelligence (AI) workflows for financial services enterprises with a no-code AI platform. Researchers, business analysts, data science teams, and developers use Accern to build and deploy AI use cases powered by adaptive natural language processing (NLP) and forecasting features. The results are that companies cut costs, generate better risk and investment insights, and experience a 24x productivity gain with our smart insights. Allianz, IBM, and Jefferies are utilizing Accern to accelerate innovation. For more information on how we can accelerate artificial intelligence adoption for your organization, visit accern.com